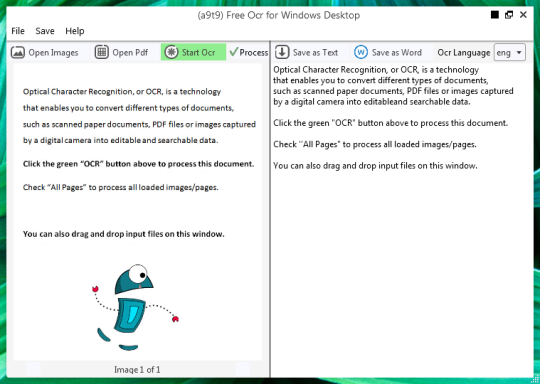
والبرمجيات الحرة OCR لاستخراج النص من ملفات الصور والعناصر PDF. واجهة المستخدم الرسومية (GUI) لمحرك تسراكت OCR.
تطبيق بسيط لتثبيت، والأهم، تتردد في استخدام ومفتوحة المصدر، و 100٪ ادواري وبرامج التجسس مجانا.
يمكنك فتح صورة أو ملف PDF. سوف يتم عرض محتوى الملف المصدر في الإطار الأيسر. إذا كان المستند كصفحة أكثر من واحد، أو إذا كنت فتح المستندات متعددة الصفحات، استخدم الأسهم في أسفل للتبديل بينهما،
بدء تشغيل OCR من خلال النقر على الزر الأخضر OCR، وسترى النتيجة في النافذة اليمنى الثاني. يمكن حفظ النص الناتج كملف نصي أو مستند Word.
للأسف جودة التحويل ليست كبيرة جدا. خلف الكواليس أنه يستخدم تسراكت المصدر المفتوح OCR المحرك. نوعية تختلف من لغة إلى لغة - لذلك يذهب إلى الأمام والاختبار إذا كانت كافية لاحتياجاتك
لمطوري البرمجيات والمهوسون: إن OCR مجانا للأداة ويندوز سطح المكتب هو في الأساس الرسومية واجهة المستخدم الأمامية (GUI) لمحرك تسراكت OCR. الكامل مصدر رمز يتوفر (رخصة GPL).
محرك OCR من البرنامج يدعم لغة OCR التالية: الإنجليزية والفرنسية والإيطالية والألمانية والإسبانية والبرتغالية البرازيلية والهولندية. بدءا من الإصدار 3 لا يمكن أن تعترف العربية، البلغارية، الكاتالانية، الصينية (المبسطة والتقليدية)، الكرواتية، التشيكية، الدانمركية، الهولندية، الإنجليزية، الألمانية (معيار وFraktur النصي)، اليونانية، الفنلندية، الفرنسية، العبرية، الهندية، الهنغارية، الإندونيسية، الإيطالية، اليابانية، الكورية، اللاتفية، الليتوانية، النرويجية، البولندية، البرتغالية، الرومانية، الروسية، الصربية، السلوفاكية (معيار وFraktur النصي)، السلوفينية، الإسبانية، السويدية، التغالوغ، والتاميلية، والتايلاندية والتركية والأوكرانية والفيتنامية.
لم يتم العثور على التعليقات