
PDF Extractor SDK لمطوري برامج Windows: PDF إلى نص ، PDF إلى XML ، صور من PDF ، قراءة معلومات PDF ، PDF إلى CSV لـ Excel.
Bytescout PDF Extractor يسمح SDK لتحويل PDF إلى نص ، PDF إلى XML ، PDF إلى CSV ، استخراج صور من PDF ، استخراج معلومات حول ملفات PDF في واجهات .NET و ActiveX بدون الحاجة إلى أي برامج إضافية.
فوائد:
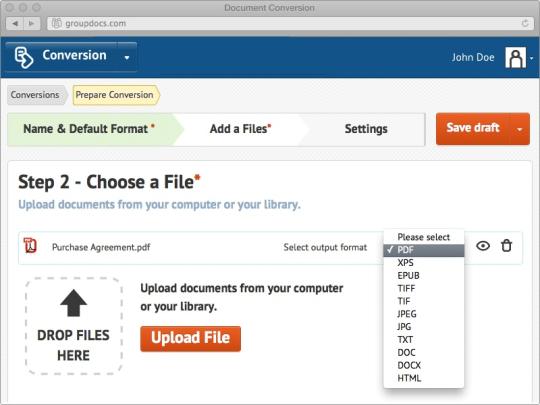
يحول PDF إلى نص عادي (ويمكن متابعة الأعمدة إذا قمت بتحويل صحيفة بتنسيق PDF) - بما في ذلك استخراج النص غير المرئي ؛
يحول الجداول في PDF إلى Excel (CSV) عن طريق قراءة الخلايا من مستطيل معين؛
يحول الجداول في ملفات PDF إلى XML.
مقتطفات من بيانات ملف PDF (العنوان ، المؤلف ، الوصف) والحصول على معلومات أخرى عن الملف (عدد الصفحات المشفرة أو غير المشفرة) ؛
استخراج الصور المضمنة من وثيقة PDF (في ASP.NET و VB.NET و C # و VB6 و VBScript) ؛
واجهات DocumentMerger و DocumentSplitter والفئات لدمج وتقسيم مستندات PDF ؛
لا يتطلب تثبيت برنامج Adobe Reader أو أي برنامج قارئ PDF آخر ؛
يوفر واجهات .NET و ActiveX ؛
مع رمز C # مدارة 100٪.
الجديد في هذا الإصدار:
الإصدار 9.0.0.3079: تمت إضافة تصفية المحتوى المستخرج بحسب اسم الخط وحجمه ولونه.
تحديث محرك OCR إلى أحدث إصدار. قم بتحديث ملفات اللغة من مجلد 'tessdata'.
تحسين استخلاص النص ، تجميع الخطوط في البيانات المجدولة ، الأداء ، استخراج نماذج XFA ، TableDetector ، مشكلات تحليل PDF الثابتة.
ما هو الجديد في الإصدار 8.7.0.2980:
إضافة التصفية المستخرجة المحتوى حسب اسم الخط وحجمه ولونه.
تحديث محرك OCR إلى أحدث إصدار. قم بتحديث ملفات اللغة من مجلد 'tessdata'.
تحسين استخراج النص ، تجميع الخطوط في البيانات المجدولة ، الأداء ، استخراج نماذج XFA ، TableDetector ، مشكلات تحليل PDF الثابتة.
ما هو الجديد في الإصدار 8.6.0.2911:
إضافة التصفية المستخرجة المحتوى حسب اسم الخط وحجمه ولونه.
تحديث محرك OCR إلى أحدث إصدار. قم بتحديث ملفات اللغة من مجلد 'tessdata'.
تحسين استخلاص النص ، تجميع الخطوط في البيانات المجدولة ، الأداء ، استخراج نماذج XFA ، TableDetector ، مشكلات تحليل ملفات PDF الثابتة.
ما هو الجديد في الإصدار 8.2.0.2699:
الإصدار 8.2.0.2699 قد تتضمن تحديثات غير محددة أو تحسينات أو إصلاحات للأخطاء.
ما هو الجديد في الإصدار 8.0.0.2528:
تمت إضافة التصفية للمحتوى المستخرج بحسب اسم الخط وحجمه ولونه.
تحديث محرك OCR إلى أحدث إصدار. تحديث ملفات اللغة من مجلد "tessdata".
تحسين استخراج النص.
تحسين خطوط التجميع في البيانات المجدولة.
تحسين الأداء.
تحسين XFA أشكال استخراج.
تحسين TableDetector.
قضايا تحليل pdf ثابت.
الصور الثابتة JBIG فك.
ImageExtractor: استخراج صورة ثابتة لكل صفحة.
MultimediaExtractor: استخراج ثابت على صوت MPEG مضمن.
TextExtractor: ثابت خاصية RemoveHyphenation غير العاملة.
تحسينات طفيفة أخرى وإصلاحات للأخطاء.
ما هو الجديد في الإصدار 7.0.0.2474:
الإصدار 7.0.0.2474:
إضافة فئة الأداة المساعدة DocumentPrinter الجديدة التي تسمح بطباعة مستندات PDF بصمت (بدون أي مربعات حوار للمستخدم)
إضافة فئة JSONExtractor جديدة
إضافة تجاوز لأسلوب DocumentSplitter.Split () السماح لتحديد مجلد الإخراج للملفات التي تم إنشاؤها
إصلاح الخلل المتعدد في برنامج DocumentSplitter
يحترم tableDetector الآن منطقة الاستخراج التي تم تعيينها بواسطة طريقة SetExtractionArea ()
خصائص جديدة في فئات الاستخراج: ExtractionColumns - تحتوي على إحداثيات الأعمدة المكتشفة ؛ CustomExtractionColumns - يسمح لتجاوز كشف العمود
أساليب GetPageRect * لم تأخذ دوران الصفحة في الاعتبار.
تم إصلاح الأخطاء الثابتة في المثبت مما تسبب في بعض الملفات من التثبيت السابق مع التحديثات
إعادة صياغة فحص التسجيل. الآن لن تقوم المكتبة بطرح استثناء ، ولكن تعمل في وضع العرض إذا فاتتك أو أدخلت خطأ RegistrationName و RegistrationKey
PDF Multitool: تمت إضافة قائمة المستندات الحديثة إلى زر "Open PDF Document"
PDF Multitool: يمكن تغيير حجمها الآن
PDF Multitool: مضاف مقتطف JSON الميزة
PDF Multitool: تحسين واجهة جهاز الكشف عن الجدول
PDF Multitool: تم تحسين جودة عرض الخطوط بشكل كبير
PDF Multitool: تمت إضافة خيار debug "Show Detected Extraction Columns" إلى قائمة السياق لعرض الأعمدة المكتشفة في الصفحة الحالية. تصبح مرئية فقط بعد تشغيل أي استخراج مقابل الصفحة الحالية المعروضة
PDF Multitool: مشكلة تقديم الخطوط الثابتة في Windows 32 بت
تحسينات طفيفة أخرى وإصلاحات الأخطاء
ما هو الجديد في الإصدار 6.30.0.2421:
الإصدار 6.30.0.2421:
إضافة فئة الأداة المساعدة TextComparer (متوفرة في تجميعات NET 4.0 فقط) مما يسمح بمقارنة النص في مستندين PDF وإنشاء تقرير.
دعم محسّن لمحات اللون ICC.
معالجة مبسطة للخطوط المضمنة.
المرفقات المحسنة Extractor.
تم إصلاح طريقة XMLExtractor.SaveXMLToStream ().
ثابت تكرار النص المستخرج عند استخدام الخيار OCRCacheMode.WholePage.
إصلاحات الأخطاء والتحسينات الأخرى.
ما هو الجديد في الإصدار 6.20.2354:
الإصدار 6.20.2354:
PDF إلى نص ، PDF إلى CSV ، PDF إلى وظائف XML المحسنة
جديد استخراج فيديو ، استخراج أمثلة الصوت
تحسين مستخلصات CSV و XML لدعم الجداول ذات الأعمدة الفارغة بالداخل
new MultimediaExtractor لاستخراج الفيديو والصوت من قوات الدفاع الشعبي
خاصية جديدة PageDataCaching
مثال جديد "MemoryCareProcessingOfHugeFiles"
إصلاح استثناء خالٍ عند محاولة التخلص من الصفحات التي تم التخلص منها بالفعل
XLSExtractor: يحسن دعم الخطوط
يتخطى SkipInvisibleText الآن النص المقطّع (غير المرئي)
تحسين إخراج النص تحسن
XFDF Extractor: إضافة دعم لمربعات الاختيار
تم تحسين إخراج الصور لدعم المزيد من التنسيقات الفرعية
تحسّن معالجة نص Unicode
ما هو الجديد في الإصدار 6.11.2149:
الإصدار 6.11.2149:
يتم تحديث عينات معالجة الدُفعات لإظهار استخدام أسلوب Reset ()
تمت إضافة نموذج التعليمات البرمجية المصدر C ++ من أجل استخراج الصفحات
يضيف DocumentMerger أسلوب Merge2 (inputfile1، inputfile2، outputfile) لدمج ملفات 2
XLS Extractor إصلاح الأخطاء الطفيفة
يتيح PDF Multitool الآن تمكين / تعطيل النصوص ، الصور ، طبقات المتجهات ، يضيف إعدادات متقدمة لاستخراج النص
XML ، CSV ، استخراج الجدول يحسن دعم الجداول التي تحتوي على خلايا emtpry داخل الأعمدة
تم تحسين خاصية .ExtractShadowLikeText: فلترة أفضل للنص الذي يشبه الظل
ما هو الجديد في الإصدار 6.10.2136:
الإصدار 6.10.2136:
PDF إلى XML ، PDF إلى CSV ، تم تحسين وظيفة PDF To Text
PDF إلى نموذج سطر الأوامر XLS المضافة (على أساس vbscript)
PDF إلى HTML يضيف SDK خاصية .DetectHyperLinks جديدة (TRUE افتراضيًا) لتمكين / تعطيل اكتشاف الارتباطات الآلية في النص
جديد SearchablePDFMaker (متاح لتراخيص PRO) لتحويل PDF إلى ملفات PDF قابلة للبحث
خصائص جديدة في مستخرج: ConsiderFontNames، ConsiderFontSizes، ConsiderFontColors، ConsiderVerticalBorders في ملفات CFG
الكشف عن الأعمدة الرأسية (عندما يتحسن AutoAlighHeaderToColumns = true)
استبدال .DetectLinesInsteadOfParagraph مع .LineGroupingMode جديدة للتحكم في كيفية دمج الخطوط في الفقرات
مهم! PDF إلى XML بإصلاح مشكلة وقت طويل مع إحداثي ص غير صحيح لكائنات النص (كان يشير إلى أسفل اليسار بدلاً من أعلى اليسار)
.TableXMinIntersectionRequiredInPercents و .TableYMinIntersectionRequiredInPercents تم إضافة الخصائص
تمت إضافة نموذج التعليمات البرمجية المصدر C ++
يقوم XML Extractor بإصلاح الأعمدة الفارغة المفقودة في PreserveFormatting = الوضع الصحيح
إصلاحات طفيفة في الألوان في بعض ملفات PDF
دعم العديد من لغات التعرف الضوئي على الحروف المضافة
PDF Multitool واجهة المستخدم الرسومية: إضافة زر نسخ إلى الحافظة إلى مربعات حوار TXT و CSV و XML و rasterer
XLSExtractor: يضيف خاصية PageToWorksheet لتمكين / تعطيل إنشاء أوراق عمل منفصلة لكل صفحة
خاصية .TextEncodingCodePage جديدة
PDFViewerControl: يضيف ValidateContextMenu مما يسمح للمستخدم بإضافة عناصر مخصصة إلى قائمة السياق
عنصر تحكم عارض PDF: يضيف خصائص ShowTextObjects و ShowImageObjects و ShowVectorObjects
يقوم XMLExtractor الآن بإضافة سمة "OCRConfidence" للنص الذي تم التعرف عليه
PDF / وظيفة التحقق (في الإصدار التجريبي)
تحسين عناصر التحكم وفحص النص والمحاذاة وفقًا للتخطيط الأصلي. نشأت المشكلة عن تغيير إحداثيات Y في عناصر التحكم أثناء التحليل: وكان ذلك غير صحيح. الطريقة الصحيحة هي ...
XML Extractor المحدّث: ينتج الآن علامة CONTROL for checkboxes وحقول النص
تغيرت باستخدام الدليل الحالي إلى الدليل المؤقت
هي أفضل دعم مربعات الاختيار ، radioboxes ، editboxes ، comboboxes
يسمح الآن المتصلين بالثقة الجزئية
ما هو الجديد في الإصدار 5.80.1781:
الإصدار 5.80.1781:
PDF إلى XML ، PDF إلى CSV ، PDF إلى وظيفة النص المحدثة
يوفر OCRMode الآن 9 أوضاع
.DetectLineInsteadOfParagraph الآن يعمل بشكل أفضل بكثير. اضبطه على False لالتقاط نص متعدد الأسطر في خلايا الجدول!
دعم ضوابط قوات الدفاع الشعبي تحسين
استخراج البيانات FDF و XFDF
ما هو الجديد في الإصدار 5.10.1747:
الإصدار 5.10.1747:
PDF إلى XML ، PDF إلى CSV ، PDF إلى وظائف النص المحسنة
يدعم الآن استخراج النص من عناصر التحكم في النص
يضيف XML extractor الآن نمط الخط والحجم والاسم وإحداثي النص إلى العلامات
إضافة نموذج ASP.NET لاستخدام OCR
خاصية جديدة OCRLanguageDataFolder لتحديد موقع مجلد "tessdata"
تحسين دعم ملفات PDF
يحسن الدعم للنص استدارة
عينات التعليمات البرمجية المصدر المحدثة
وثائق محدثة
تحسينات طفيفة واصلاحات
ما هو الجديد في الإصدار 5.00.1626:
الإصدار 5.00.1626:
إضافة وظيفة التعرف الضوئي على الحروف (النص من الصور): يمكنك الآن استخراج النص من الصور المضمنة وإصلاح النص التالف
مشكلة ثابتة مع CSV ومستخرج XML في عداد المفقودين الأعمدة الماضية مع بعض الإعدادات
تحسين الدعم لملفات PDF التالفة
البحث بنص البحث متعدد الأسطر مع صيغ مطابقة الكلمات مدعوم الآن
الآن قد البحث في النص مع الواصلات وعلى أسطر مختلفة: راجع نموذج التعليمات البرمجية المصدر الجديد البحث عن نص باستخدام الواصلات
خاصية جديدة .RTLTextAutoDetectionEnabled (false افتراضيًا) للكشف التلقائي عن لغات RTL
تحسين PDF عارض واجهة المستخدم الرسومية التجريبية
تحسينات طفيفة واصلاحات
المتطلبات:
.NET Framework 2.0 أو أعلى
القيود:
شاشة Nag ، العلامة المائية على المخرجات
لم يتم العثور على التعليقات